仅缩小视觉Token位置编码间隔,轻松让多模态大模型理解百万Token!清华大学,香港大学,上海AI Lab新突破
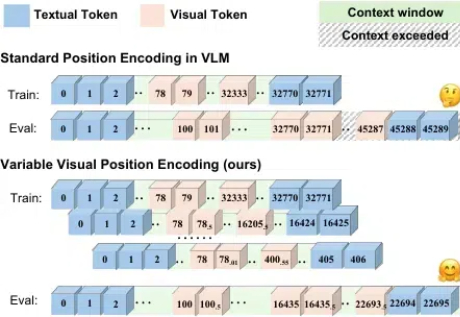
仅缩小视觉Token位置编码间隔,轻松让多模态大模型理解百万Token!清华大学,香港大学,上海AI Lab新突破随着语言大模型的成功,视觉 - 语言多模态大模型 (Vision-Language Multimodal Models, 简写为 VLMs) 发展迅速,但在长上下文场景下表现却不尽如人意,这一问题严重制约了多模态模型在实际应用中的潜力。
来自主题: AI技术研报
9391 点击 2025-01-15 14:23